Earlier this spring, Education Next published an article by Paul T. von Hippel and Laura Bellows questioning whether it was possible to distinguish one teacher preparation program from another in terms of their contributions to student learning. Looking at data from six states, von Hippel and Bellows found that the vast majority of programs were virtually indistinguishable from each other, at least in terms of how well they prepare future teachers to boost student scores in math and reading.

Paul T. von Hippel
Much of the national conversation around teacher preparation focuses on crafting minimum standards around who can become a teacher. States have imposed a variety of rules on candidates and the programs that seek to license them, with the goal of ensuring that all new teachers are ready to succeed on their first day in the classroom. Von Hippel and Bellows’ work challenges the very assumptions underlying these efforts. If states cannot tell preparation programs apart from one another, their rules are mere barriers for would-be candidates rather than meaningful markers of quality. Worse, if we can’t define which programs produce better teachers, we’re left in the dark about how to improve new teachers.
To probe deeper into these issues, we reached out to von Hippel, an associate professor at the University of Texas at Austin. What follows is an edited transcript of our conversation.
Bellwether: Can you start off by describing your work on teacher preparation? What compelled you to do the work, and what did you find?
von Hippel: It started with a 2010 contract that some colleagues and I at the University of Texas had with the Texas Education Agency. Our contract was to develop a pilot report card for the nearly 100 teacher preparation programs in the state of Texas. The idea was to come up with a teacher value-added model and then aggregate teacher value-added to the program level. We would then figure out which programs were producing better and worse teachers in the state, with the idea that the state would at a minimum provide feedback, encourage programs that were producing effective teachers and ideally expand them, and, in extreme cases, shut down programs that were producing a lot of ineffective teachers.
Once we got going, we found that most programs really didn’t differ very much in teacher value-added. Although there were better and worse teachers, it was not the case that the better teachers were concentrated in certain programs. There were just very minimal differences between programs — differences so small that it wouldn’t make sense to take policy action on them. There was one program that seemed to stand out as preparing pretty bad math teachers and one program that stood out as preparing pretty good reading teachers. But for the most part, the one hundred or so programs in Texas were undifferentiated.
Bellwether: What should we do with the information that it’s very difficult to distinguish most programs from each other, and that there might be only a few outliers at the top or bottom end? Can we use it for policy? Can we pinpoint what makes low performers bad and what makes higher performers more effective?
von Hippel: I think it is possible in some states to identify one or two programs that are really doing a great job and really turning out great teachers, and maybe one or two programs that are turning out very poor teachers. When studies are conducted properly, 90 percent of the programs can’t be distinguished, but there are one or two standouts at either end.
Unfortunately, that is not how state regulations are currently written, and it’s not how the short-lived federal regulation that was published in 2016 was written. There, the expectation seems to be that you’re effectively going to be able to rank all the programs and put them in four or five broad categories: low-performing, at risk, effective, exemplary… and it’s just not possible to do that. For the most part, you just can’t differentiate the programs except for one or two outliers.
If the regulations were written with that understanding, then I wouldn’t have such an issue with them. But they’re written with the objective of effectively ranking every program in the state, and I think when you do that you’re effectively going to be ranking programs on noise.
Bellwether: Do you think there’s anything we could learn from digging deeper into those outliers?
von Hippel: I don’t think it makes sense to take action based on value-added numbers alone, especially since there are so few programs that are going to stand out at one end or the other of the continuum. I would say if you’ve carried out one of these analyses — and we’ve issued software that we think does a better job than existing methods at singling out programs that really do appear to be different — you’re going to have one or two programs in your state at most that stand out. And that being the case, hopefully you have the resources to visit those programs and see if they’re doing anything special. So you can follow up qualitatively.
Bellwether: How should we reconcile research on single teacher preparation programs — such as positive reviews of Teach For America and UTeach — versus your work suggesting that very few programs stand out from the crowd?
von Hippel: Let me start by answering the question I thought you were going to ask, and then I’ll answer the question you actually asked.
What I thought you were going to ask was how we reconcile the small differences we found in Texas with the large differences that have been reported in other states like New York and Louisiana. We were confused about that for a while. Then the Missouri results came out suggesting that they were also finding very small differences there, and that bolstered our confidence. But we still wondered what was going on in New York and Louisiana. So, the paper that we published in January was largely about going back to the New York and Louisiana results and re-analyzing them, along with results from Texas, Missouri, Florida, and Washington state.
In the end, we found that there really wasn’t any more evidence for large differences between programs in New York and Louisiana than there was in Texas and Missouri. In every state we’ve looked at, we’ve found very little evidence of differences between programs. This is an area where statistical methods have gotten better over time, so when you return to some earlier studies with some of the lessons learned from later studies, you sometimes find that the conclusions change. That’s what we found, and that’s why we now view the literature as being pretty consistent on the question. Within every state that we’ve looked at, we really don’t see big differences among the vast majority of programs.
That’s the question you didn’t ask. Now let me answer the question that you did.
It’s true that Teach For America and UTeach tend to turn out above-average teachers, although their effects aren’t huge and tend to be limited to math and STEM fields. Our results don’t contradict that. We didn’t find that all programs are indistinguishable, only that the vast majority are indistinguishable. One or two might stand out, so there’s definitely room for a UTeach or a Teach For America to distinguish itself.
That said, there are reasons why a program like Teach For America or UTeach might not stand out on a particular state report card. Those reasons have nothing to do with the statistics of value-added, but come down to the nitty-gritty details about how exactly a “program” is defined. In the state of Texas, for example, the Texas Education Agency defines a teacher preparation program as the program that certified someone to teach. Teach For America doesn’t certify teachers in Texas, or anywhere, so Teach For America is not a program under the Texas definition. Teach For America’s teachers are attributed to the various programs that they partner with for certification in Texas, which typically certify other teachers as well. So the Teach For America teachers are sort of spread out and mixed with other teachers in various programs. There’s no Texas report card for Teach For America, and no way that Teach For America can stand out unless the state changes its definition of program.
Little details and definitions like that that can determine whether an outstanding program is even identified in a given state, and there are lots of little details like that when you look at how things are done in different states.
Bellwether: Texas is often perceived as the Wild West of teacher preparation. Its teacher preparation programs run the gamut from elite institutions like the University of Texas at Austin to weeks-long online programs. Yet you found no differences in terms of student outcomes across all these types of programs. Does that mean teacher preparation programs don’t matter? How should we reconcile your findings with the common perception of the teacher preparation landscape in Texas?
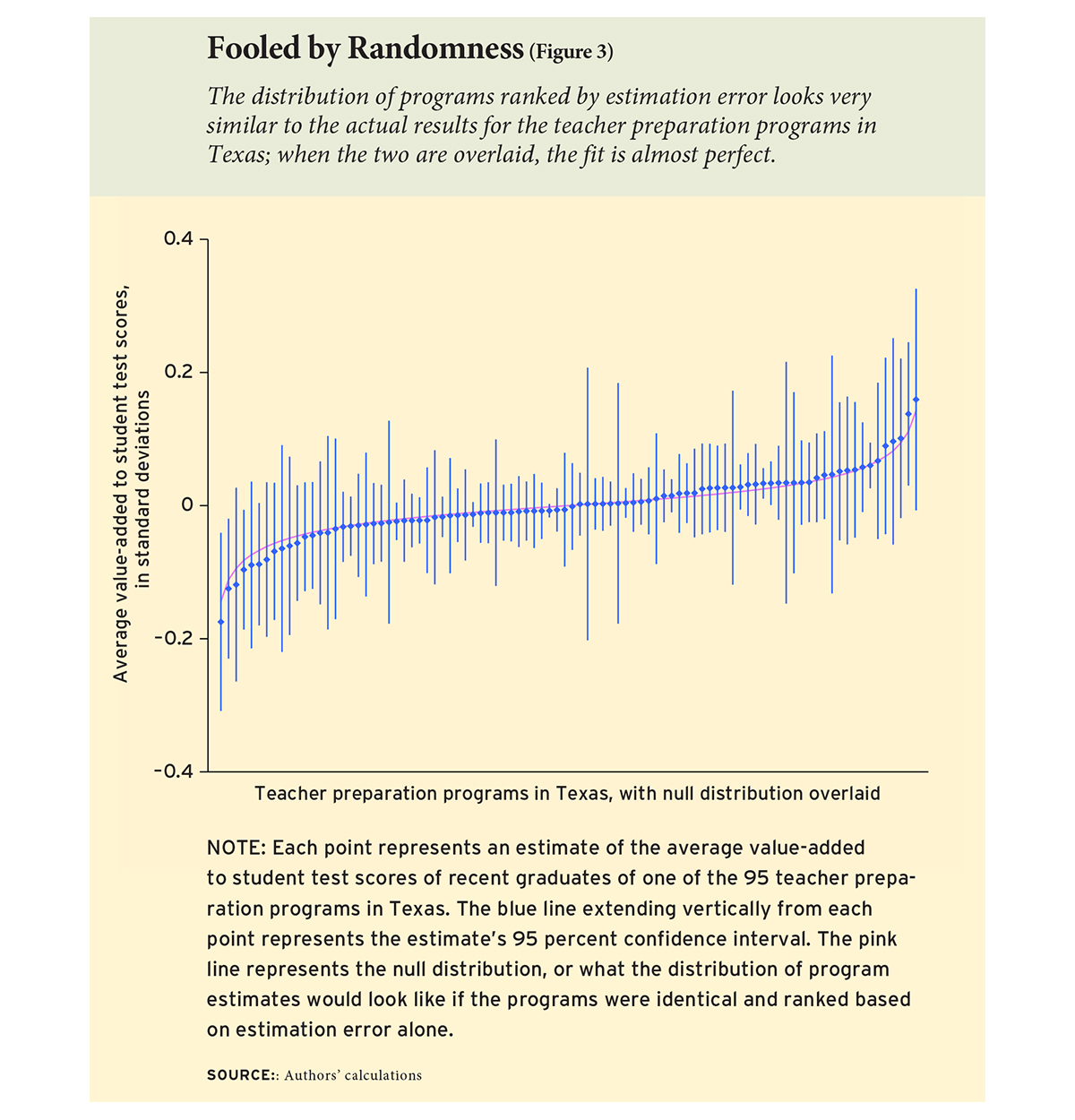
Statistically speaking, Texas teacher preparation programs produce very similar results. Source: Education Next.
von Hippel: When we looked at this situation in 2011, the four largest teacher preparation programs in Texas were all alternative programs, and three of those were run for-profit. It really is true that you see advertisements for teachers on billboards here, and that some of these for-profit programs are really quite short and provide very minimal training.
There was concern at the Texas Education Agency about programs like that, and very little was known about their quality. So I think it was a little surprising that we found what we did and that those teachers actually going into the classroom out of those programs did not differ much in their value-added from teachers who came from more traditional programs.
That said, not all the teachers who go through these short alternative programs get jobs in the classroom, and it’s the teachers who get jobs in the classroom who contribute to the value-added of those programs. That may explain why in the end we didn’t see much difference between those programs and other, more traditional, programs in the state. But that’s speculation.
There are different theories of how teacher preparation functions to ensure teacher quality. One theory is that it’s really important to have rigorous teacher preparation, which should take a while; there should be student teaching and a lot of pedagogy instruction and so on. And there’s another perspective that says extensive training sounds really good, but a lot of times the training is not really that great, is time consuming, and career changers aren’t going to want to do it. So effectively these kinds of certification requirements keep potentially effective teachers out of the classroom. You can imagine that some of these alternative certification programs get a mix of people who actually would be excellent teachers but for whatever reason can’t do a traditional program at that point in their life, and then some other folks who wouldn’t be very effective teachers. If it is a mix like that, that could explain why we don’t find much of a difference.
Bellwether: What was the reception to your work in Texas. Do people believe it? Have they changed any of their behavior accordingly?
von Hippel: Well, it’s hard to say. We had a two- or three-year contract with the Texas Education Agency, and I have not been privy to decisions that were made after that, but if you look at their website, you will find that they are reporting metrics for each program in Texas, and those metrics include straightforward and reasonable outputs, like the percentage of applicants that a program admits, that complete the program, that pass the certification test, that enter the profession, and that are still in the profession five years later. I think those are all great things to track. They’re meaningful, they don’t require a lot of fancy modeling, and they’re straightforward to measure.
But what you won’t find in the current metrics is the average value-added by program graduates. There’s a column for it in the spreadsheet, but it’s blank. And the notes say that data for this measurement are under development and there’s currently no standard. I think that’s really interesting, because there’s a 2009 law that requires the Texas Education Agency to rate programs on teacher value-added, yet 9 years later, after extensive modeling not just by us but by other research teams, they’re describing it as underdeveloped. So they’ve come as close as they can to basically not doing it, which I think is the right decision given what’s emerged in the research. As I say, I don’t know how these decisions were made, but I’m hoping we can take a little bit of credit for the inaction.
In policy, we’d all like to do something big like launch the Peace Corps, but sometimes the best policy outcome that you can hope for is to create enough uncertainty about a tenuous idea that no action is taken on it.
Bellwether: 21 states and DC have gone through the trouble of connecting completer outcomes to the programs that prepared them. Is this wasted effort? Could the metrics still be valuable to states? Are they useful to other users, like preparation programs or prospective candidates?
von Hippel: There was a lot of enthusiasm for this idea in the mid-2000s, and I think it was premature. A lot of effort was sunk into collecting these data that might have better been used elsewhere. That said, in Texas at least, it was this initiative that caused the state to collect the data for the first time that’s needed to link teachers to students statewide. That in itself is valuable, because there are all kinds of other questions you can answer with those kinds of data. You don’t have to use them to evaluate teacher preparation programs. Knowing where your more and less effective teachers are can be valuable for lots of other reasons. To the degree that this push caused states to put this infrastructure in place, I think that it was not wasted effort.
Bellwether: Your findings have clear policy-level implications. But what do they mean for schools and districts who are trying to hire the best possible teachers right now? Can you tell them what to look for? What should prospective employers glean from your findings?
von Hippel: That’s really a different question. I think there was this idea that if you knew which programs have a stronger or worse reputation, and those reputations had an empirical basis, you could say: “Oh, we’d like to hire from that program — the teachers from there are really good.” What we’re finding is that’s not actually the case. Knowing what program a teacher comes from is not particularly predictive of how strong they’re going to be in the classroom.
This is not just true in teaching; it’s true in other fields as well. Top employers love to hire from elite universities, but where someone trained is only a weak predictor of how productive they’ll be. Even among economics professors, the best graduates from Illinois or Toronto are about as productive as the third-best graduate from Berkeley, Penn, or Yale — and way more productive than an average graduate from the latter institutions. There’s a lot of variation among individuals trained by the same institution, and the average differences between institutions are often pretty small.
This is one of a number of findings showing that a lot of the information on teachers that you have at the time of hire is not terribly predictive of how strong teachers are going to be.
There are different directions that researchers have gone with that. One direction is to try to measure a variety of characteristics, including non-cognitive skills, which might be more predictive. There’s been some research on that by Jonah Rockoff and his colleagues.
Another direction that people go in is that it’s really important to monitor teacher quality after they enter the classroom, and to be able to do something about it if the teacher shows up as being extremely effective or ineffective early in their career. But that’s difficult to do effectively because value-added estimates for individual teachers bounce around from year to year, and rise through the early years, and by the time you’re sure you have a lemon, the teacher is often out of their probationary period, with some guarantee of job security.
Bellwether: Anything else you would like to add?
von Hippel: I just wanted to follow up on the last thing I was saying, that there’s kind of a debate about what you can do to change teacher quality after teachers enter the classroom. It gets very politicized because a lot of recommended policies involve taking aggressive actions that rub teachers’ unions and many individual teachers the wrong way. For example, there was a simulation by Rockoff and Staiger suggesting that if you fired three quarters of teachers within their first three years, average teacher quality would increase. Of course, that’s not a viable policy option, especially where teachers are unionized, and if it were implemented, it would probably depress the quality of the teacher pool unless pay went up substantially, which is something that Jesse Rothstein has looked at.
It’s a difficult problem. You can’t necessarily predict which teachers are going to be effective before they enter the classroom, and after they’ve been in the classroom for a few years, it’s often difficult to take meaningful action. But it’s not a problem that’s limited to the teaching profession. Predicting and monitoring job performance is challenging in many other professions as well.